
So this is more of me just thinking out loud on how this could be accomplished. Any thoughts or comments would be appreciated. Check Dale’s blog “VMware App Volumes Multi-vCenter and Multi-Site Deployments” for a great pre-read resource.
The requirements for this solution I’m working on are for a highly available single AppVolumes instance between two highly available datacenters with a 100% VMware View non-persistent deployment. A large constraint is that block level active/active storage replication is desired to be avoided, which is largely why UIA writable volumes is such a large piece of the puzzle; we need another way to replicate the UIA persistence without leveraging persistent desktops. CPA will be leveraged for global entitlements and home sites to ensure users only ever connect to one datacenter unless there is a datacenter failure. AppVolumes and Writable UIA volumes are to be utilized to get the near persistent experience. There can be no loss functionality (including UIA applications on writable volumes) for any user if a datacenter completely fails. RTO = near 0, RPO = 24 Hours for UIA data. In this case assume <1ms latency and dark fiber bandwidth available between sites.
Another important point is that as of AppVolumes 2.9, if leveraging a multi-vCenter deployment, the recommended scale per the release notes is 1,700 concurrent connections per AppVolumes Manager, so I bumped up my number to 3 per side.
So, let’s talk about the options I’ve come up with leveraging tools in the VMware toolchest.
- Option 1a: Leveraging AppVolumes storage groups with replication
- Option 1b: Leveraging AppVolumes storage groups with replication and transfer storage
- Option 2: Use home sites and In-Guest VHD with DFS replication
- Option 3a: Use home sites and native storage replication
- Option 3b: Use home sites and SCP/PowerCLI scripted replication for writable volumes, manual replication for appstacks
- Option 4: Use a stretched cluster with active/active storage across the two datacenters
Option 1a: Leveraging AppVolumes Storage groups with Replication

The problem is AppVolumes does not allow storage group replication two different vCenter servers, and having multiple Pod vCenters is a requirement for the Always-On architecture. I read that in this community post, the error message in the System Messages reads: “Cannot copy files between different vCenters”, and a fellow technologist posted up recently and said he tried it with 2.9 and the error message still exists. So in short, Dale’s blog remains true in that storage groups can only replicate within a single vCenter, so this isn’t a valid option for multi pod View.
Option 1b: Leveraging AppVolumes Storage groups with Replication and Transfer Storage

So that’s a another pretty good workaround option. Requires a native storage connectivity between the two pods, which means there must be a lot of available bandwidth and low latency between the sites, as some users in POD2 might actually be leveraging storage in POD1 during production use. Providing you can get native storage connectivity between the two sites, this is a very doable option. In the event of a failure of POD1, the remaining datastores in POD2 will sufficiently handle the storage requests. Seems like this is actually a pretty darn good option.
** EDIT: Except that storage groups will ONLY replicate AppStacks, not writable volumes per a test in my lab, so that won’t work. Also there’s this KB stating that to even move a writable volume from one location to another, you need to copy it, delete it from the manager, re-import it and re-assign it. Not exactly runbook friendly when dealing in the thousands.
Option 2: Use Home Sites and In-Guest VHD with DFS Replication
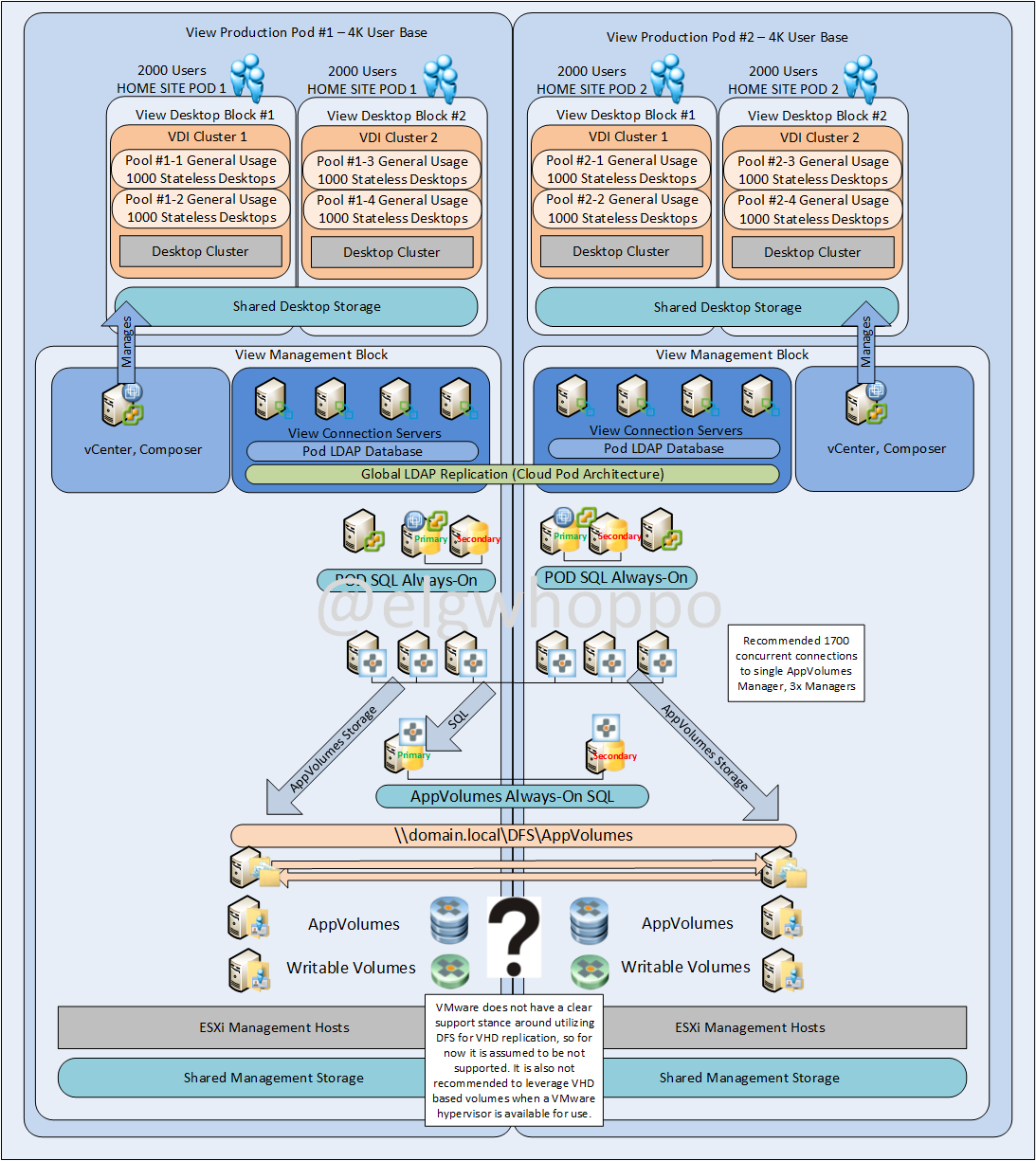
The problem with option 2 is In-Guest VHD seems like a less favorable option given that block storage should be faster than SMB network based storage, particularly when the software was written primarily to leverage hypervisor integration. I’m also not sure this configuration will even work. When I tried it in my lab, the AppVolumes agent kept tagging itself as a vCenter type of endpoint, even though I wanted it to use In-Guest mode. Tried to force it to VHD without luck. So I’m pretty sure this option as well is out for now, but the jury is still out on how smart this configuration would be compared to other options. Leveraging DFS seems pretty sweet though, the automatic replication for both AppStacks and Writables seems like a very elegant solution, if it works.
Option 3a: Use Home Sites and native storage replication

The problem with option 3 is the RTO isn’t met and it adds recovery complexity. From an AppVolumes perspective it is the easiest to carry out, as the writable volume LUNs can be replicated and the AppStack LUNs can be copied manually via SCP or the datastore browser without automatic replication. As it stands right now, I believe this is the first supported and functional configuration in the list, but the near 0 RTO isn’t met due to storage failover orchestration and appvolumes reconfiguration.
The aforementioned KB titled Moving writable volumes to new location in AppVolumes and some extra lab time indicates to me that in order to actually fail over properly, the Writable volume (since it is supposed to exist in one place only, and the datastore location is tied to the AppVolumes configuration in the database) would need to be deleted, imported and reassigned for every user of writable volumes. Not exactly a quick and easy recovery runbook.
Option 3b: Use Home Sites and SCP/PowerCLI scripted replication for writable volumes, manual replication for appstacks
This is basically option 3, but instead of leveraging block level replication, we could try to use an SCP/PowerCLI script that would copy only the writable volumes and metadata files from one vCenter to the other in one direction. Pretty sure this would just be disastrous. Not recommended.
Option 4: Use a stretched cluster with active/active storage across the two datacenters for all app stacks and writable volumes

This pretty much defeats the whole point, because if we’re going to leverage a metrocluster we can simply protect persistent desktops with the same active/active technology and the conversation is over. It does add complexity because a separate entire pod must be leveraged so that the vCenter/Connection servers can failover with the desktops, which is a large amount of added complexity. A simplified config would be just to leverage active/active storage replication for the AppVolumes storage, but that’s super expensive for such a small return. At that point might as well put the whole thing on stretched clusters.
EDIT: But then again, near zero RTO dictates synchronous replication for the persistence. If the users’ UIA applications cannot be persisted via writable volumes, they must be persisted via Persistent desktops, which will end up requiring the same storage solution. I’ve pretty much ended up back here, which is right where I started from a design standpoint.
So! If any of you guys have any input I’d be interested to hear about it. The real kicker here is trying to avoid the complexity block level active/active storage configuration. If we remove that constraint or the writable volumes from the equation, this whole thing becomes a lot easier.
EDIT: The active/active complexity for near 0 RTO can’t be avoided just yet in my opinion. At least with option 4 we would only be replicating VMDK files instead of full virtual machines. To me that’s at least a little simpler, because we don’t have to fail over connection brokers and a separate vCenter server just for managing those persistent desktops.

Is there any budget limitation or can you spend whatever you want? Similarly, what are the skillsets of the support staff responsible for maintaining this environment? 🙂
We are just starting a project very similar to yours so will keep you updated on any ideas we come up with.
These are all great thoughts around design. Have you found a way to support a cloud-pod architecture that replicates both App Stacks and Writable Volumes? Without having access to a stretch MetroCluster, 1b looks to be the best way?
This whole post needs to be revamped. What is available in 2.10 and what was announced in 3.0 are game changers for AppStacks, not so much for writables.
Well, I’m deploying this now so can’t really wait for 3.0 🙂 It would be nice if VMware would consider Cloud Pod Architecture for App Stacks AND Writable Volumes. As it stands now it doesn’t seem to make sense to deploy floating desktops with AS and WV in a Cloud Pod since the WV can’t be recovered for a large number of desktops within a reasonable RTO.
@elgwhoppo – Where can I get my hands on those Visio/PP shapes you used for AppStacks and Writable Volumes in your diagrams above?
Well, I am glad that I am not the only one that is running into this issue and wanting to pull out his hair because of it.
Hah, yeah. I’ve actually taken the stance to avoid writable volumes altogether because of it. AppToggle in 3.0 should address a lot of the issues with the 15 AppStack limitation. Besides, you want your staff installing apps usually not users. “usually”. : )
Is there any special app volumes related configuration for SQL Always on? Specific settings?
Option 1a: Leveraging AppVolumes Storage groups with Replication : This options works with App-Volume 2.10 and later . I have it deployed for one of our customer and its working great . Now what we plan to do is expand it to third site . Any thoughts around it would be of great help !!! .
And great job on this post .
I know this is years later, but wondering if you ever found a good solution for this in AV 2.x or 4.x? We have a multi-pod active/active/active CPA config also, and finding it very challenging to find a way to deliver a “persistent” desktop experience in that model.
I’ve moved off EUC from a career perspective, but my take has moved to just deliver entirely persistent desktops traditionally managed and back them up with a plan to restore somewhere else quickly. I’d recommend building out an empty AD/Connection Server infrastructure and rehearse restoring from a weekly desktop backup and go from there. It’s lame, but it’s so much easier.