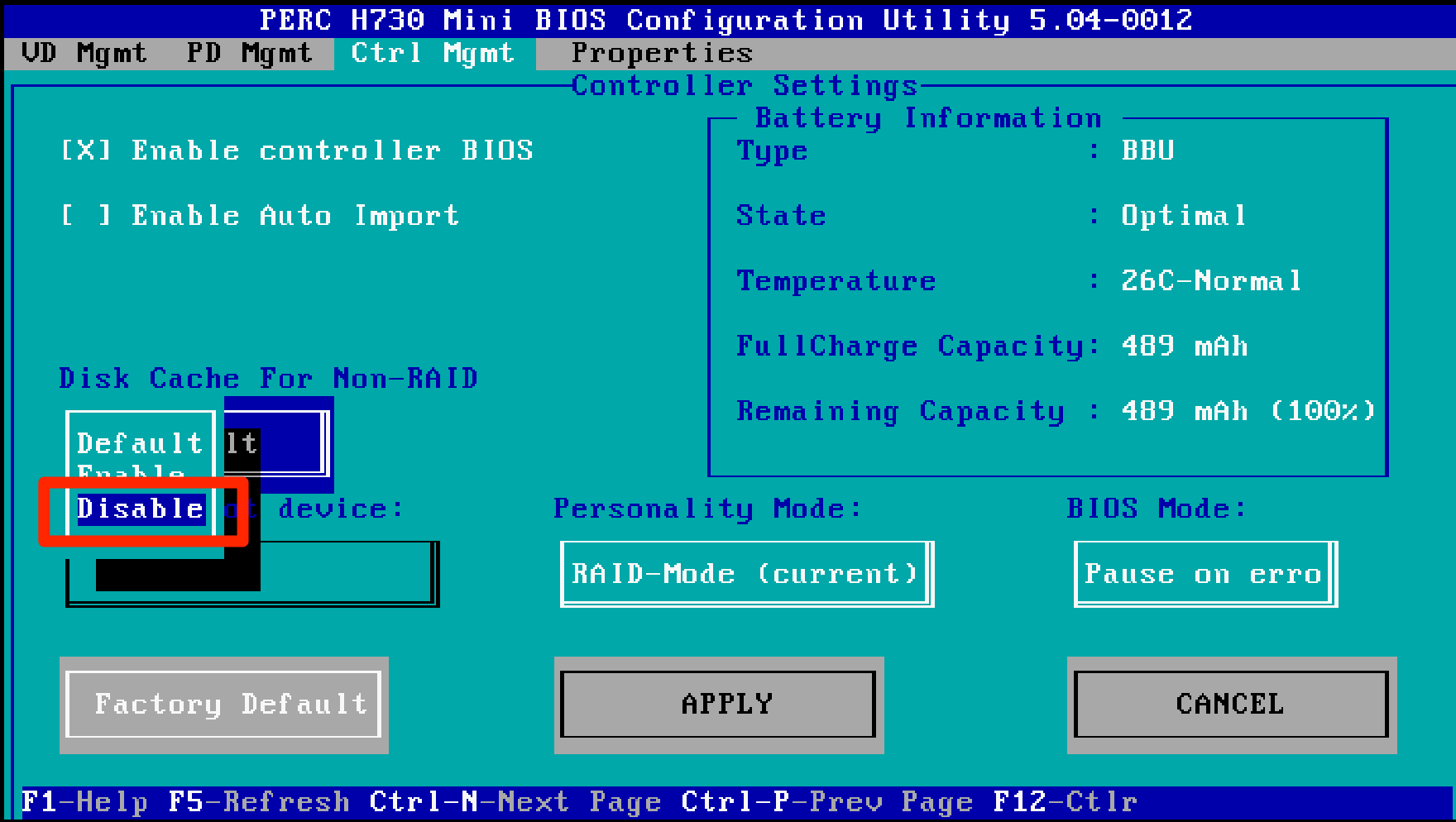
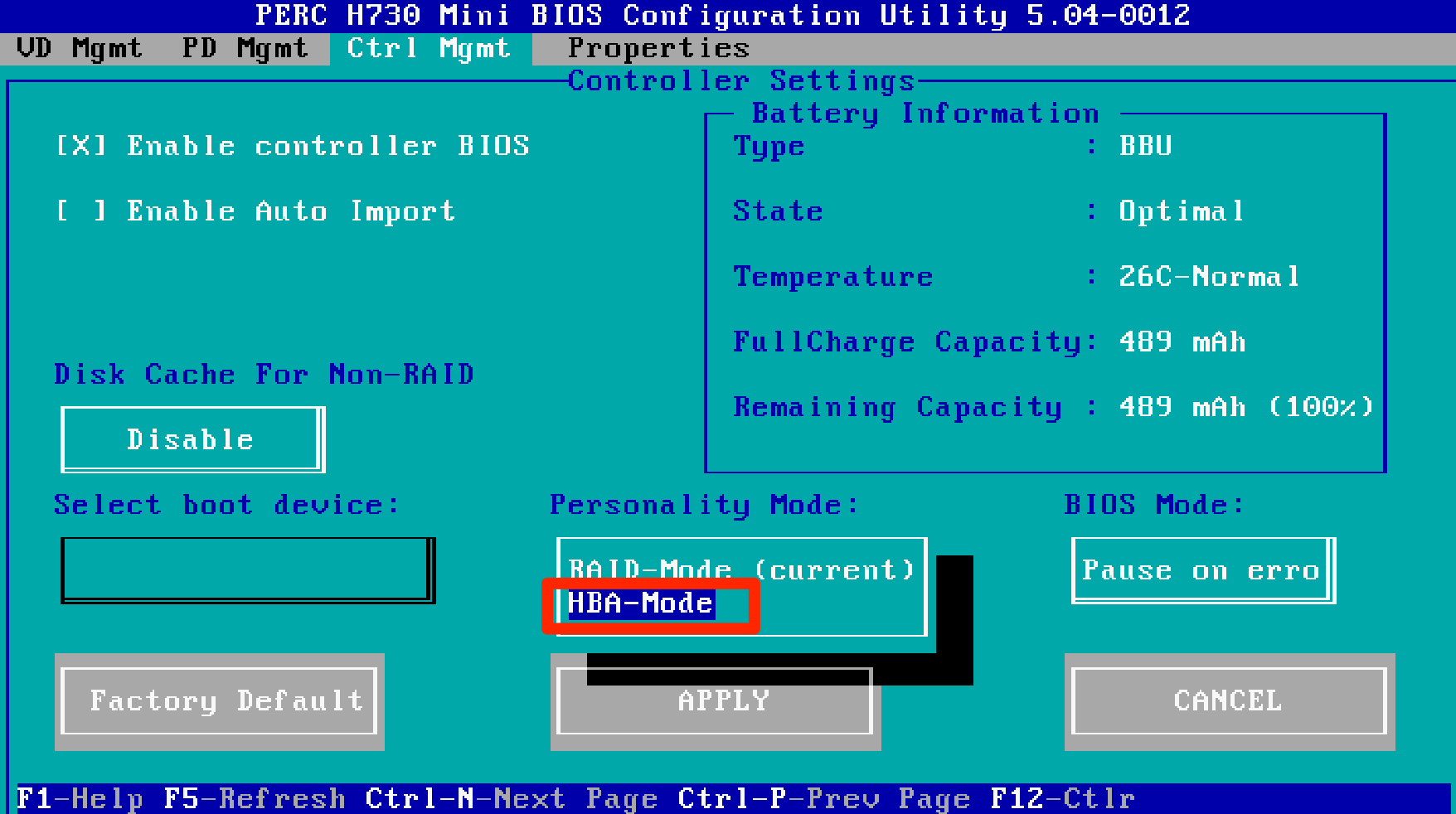
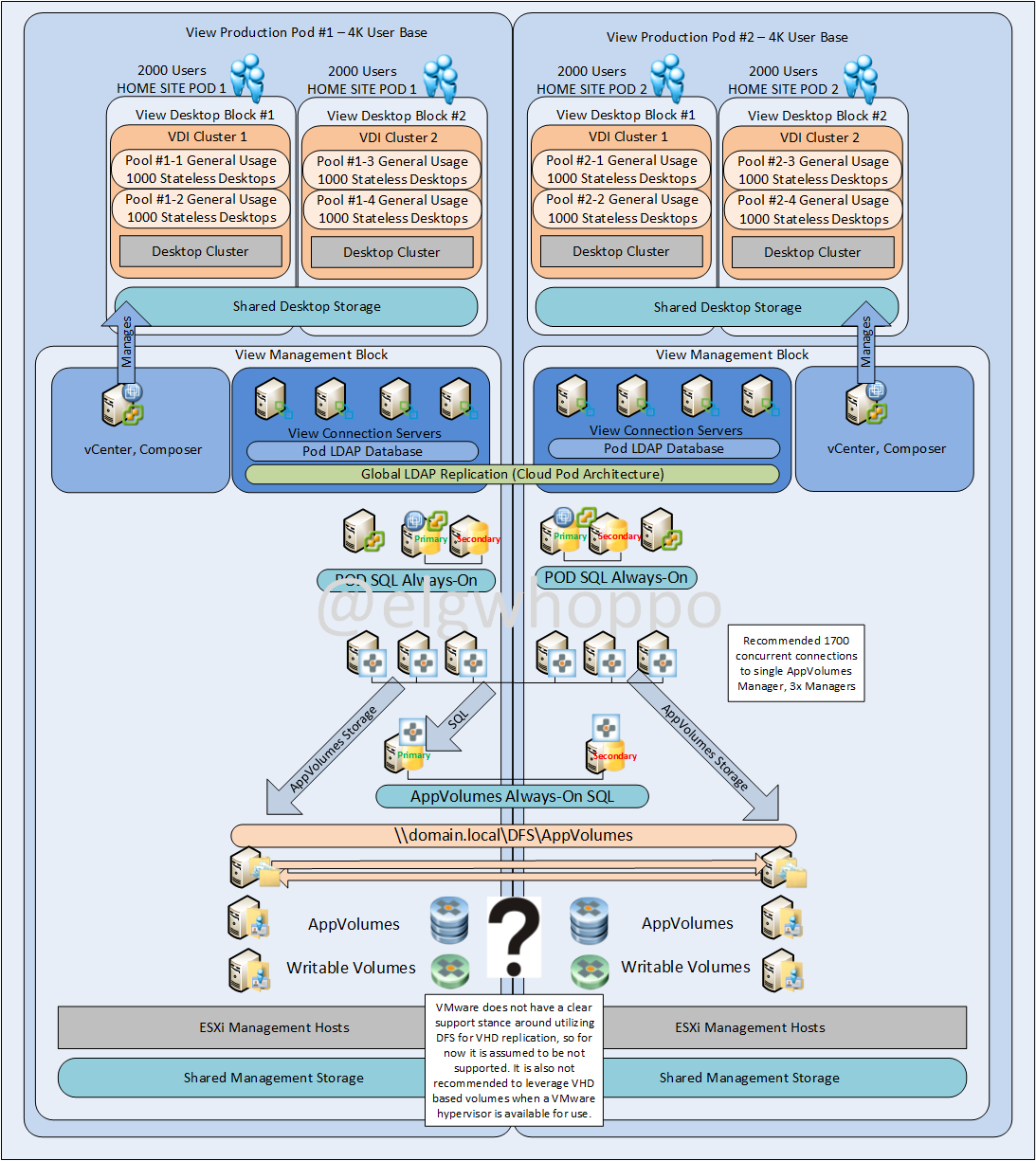
EDIT: 8/28/2016 There’s now a fling that will automatically prep rules and security groups for you. https://labs.vmware.com/flings/horizon-service-installer-for-nsx
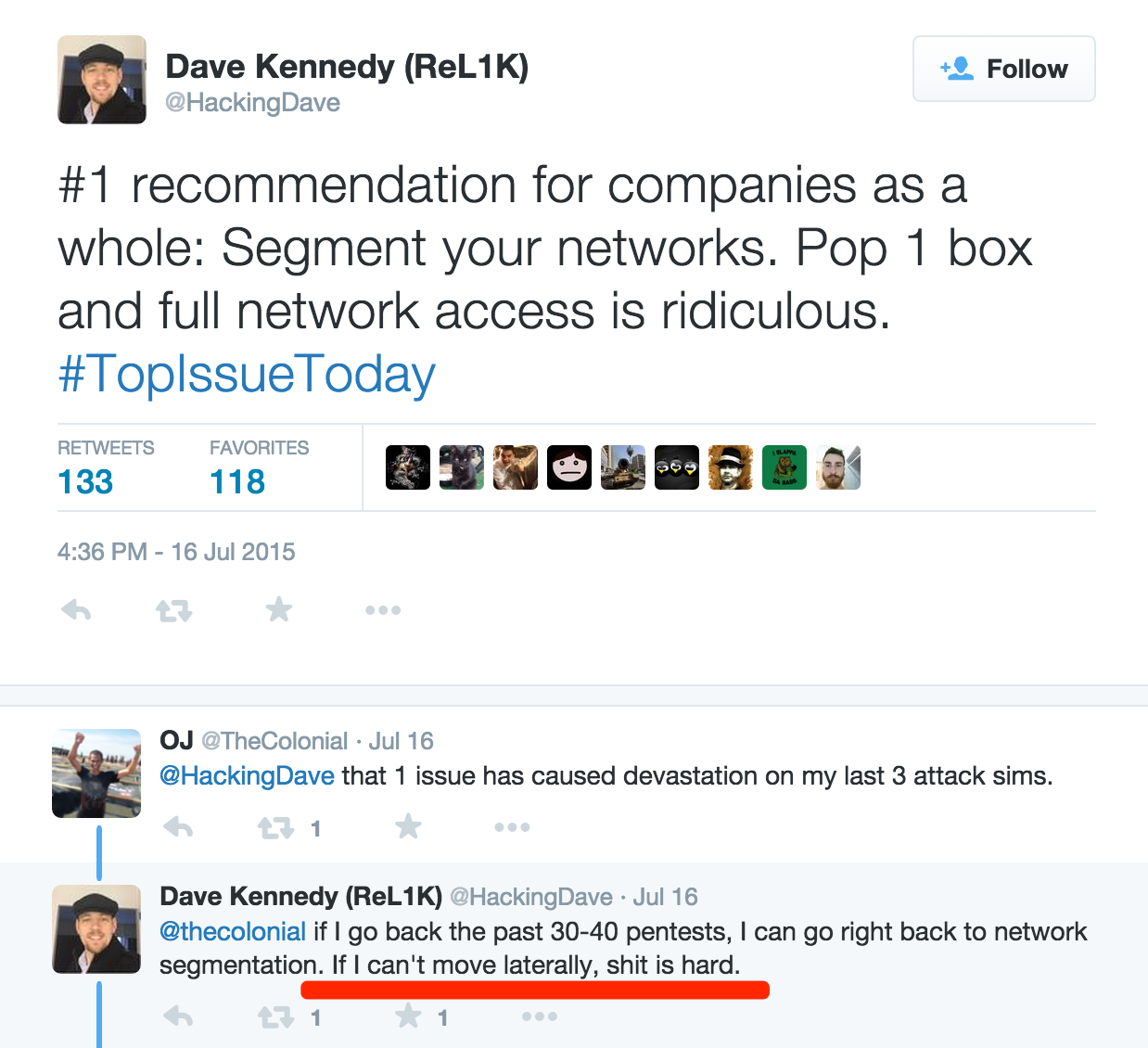
Dave Kennedy is a netsec veteran and industry leader in the information security space, has written multiple books on the topic of penetration testing, is the founder of @TrustedSec, wrote the Social Engineering Toolkit, founded @Derbycon and on and on. Point is dude knows how to find a way in and pop a box like a boss. Check out this tweet he had not too long ago.
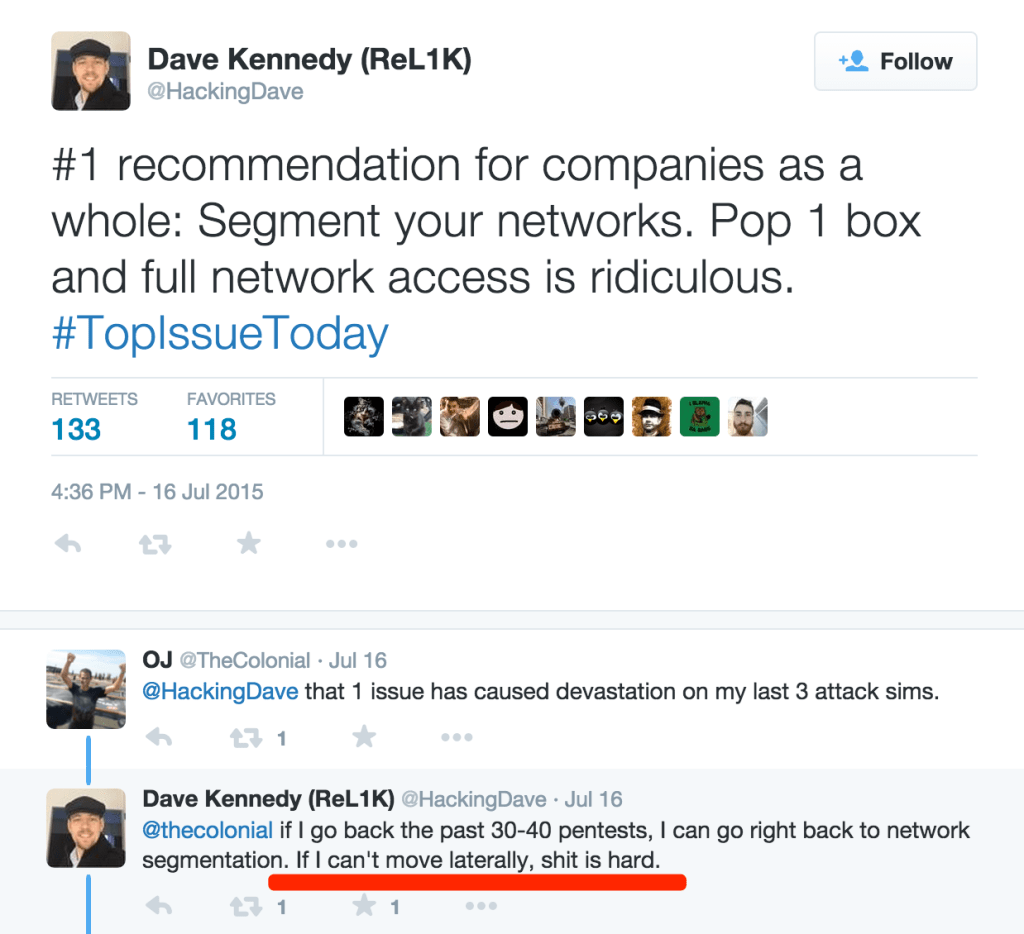
And with that red underlined statement, in my mind the micro segmentation use-case for VMware NSX speaks for itself. One of the easiest places to get access to from the outside is a user’s desktop, simply because users (often times helpdesk) can be tricked into going to a malicious website which can exploit the user’s desktop. We see this time and time again with not just email attachment, but phone spear phishing as well. Protecting the virtual desktops and servers with the DAPE model (Deny All Permit Exception) is becoming not a nice thing to have, but a near requirement for many businesses. One which security and networking teams are having a hard time doing once inside the perimeter and underneath the DMZ, especially with east west traffic inside defined networks.
It is for this reason I have been working the past few weeks on integrating NSX 6.2 and Horizon View 6.1 in my lab to implement not only zero trust desktops, but an entire zero trust hardened Horizon View Infrastructure. To me, a zero trust network infrastructure is pretty much like getting network access on a “need to have basis”. Unless specifically allowed (by policy), you’re blocked (by policy); not by traditional IP based rules. The pieces I set up in my lab include minimum functional connectivity to service the following components and services:
- Horizon View Connection Servers
- Horizon View Security Servers
- Connectivity with vCenter and Horizon View Composer
- Virtual Desktops with Identity based Firewall
NSX Load Balancers (will do a separate post for this)
Let’s take a look logically at how the lab network is set up. It’s important to remember that while I set these up with NSX based logical networks for scalability, the NSX DFW (distributed firewall) does not require any NSX logical networks to function; the DFW can work just fine even with standard virtual switching because the firewall lives in the ESXi kernel.
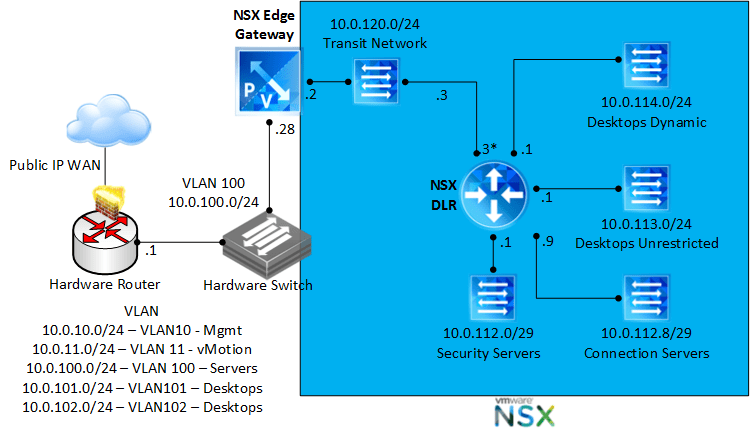
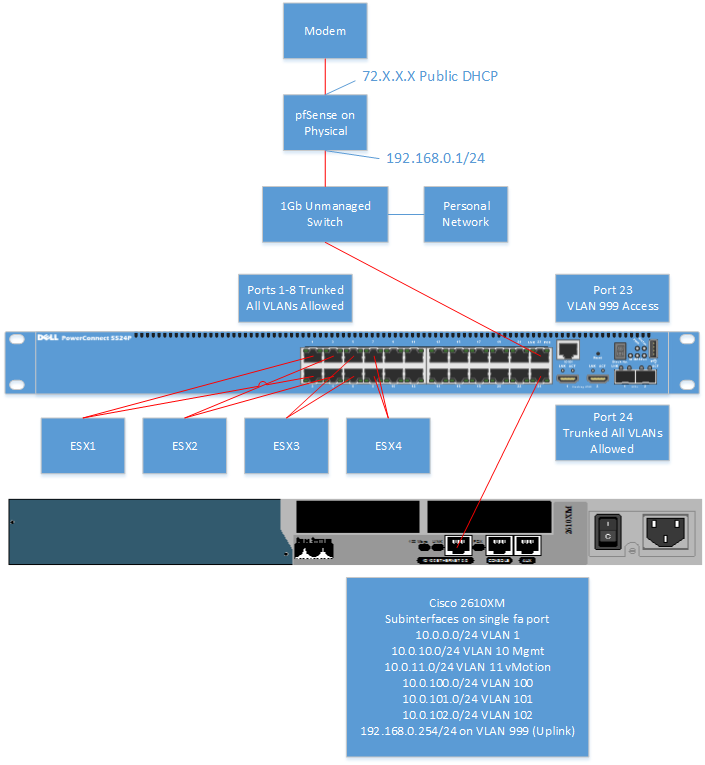
Now let’s take a look physically at how this simple lab is set up.
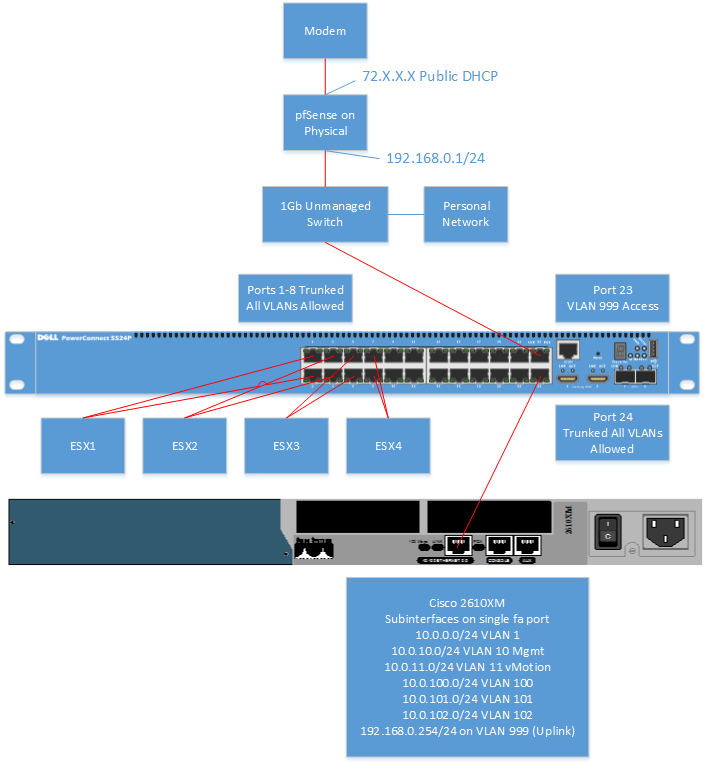
Now let’s talk about some of the View components and what east-west and north-south we firewall rules we conceptually need to make to create to harden the horizon environment, not including user defined rules. The below generic categories are in regards to traffic we need to concern ourselves with. Remember, we are not providing and open IP stack, rather providing only the required ports for the software to function. Most of these ports can be found at the KB which defines
View connectivity requirements.
Security Server
View Security Servers <–> HTTPS, PCoIP, Blast
View Security Servers <–> Virtual Desktops
View Security Servers <–> Virtual Desktops
Block the rest
Connection Server
View Connection Server <–> vCenter Server
View Connection Server <–> View Replica Server
View Connection Server <–> Virtual Desktops
View Connection Server <–> AD/DNS
View Connection Server <–> View Security Server
View Connection Server <–> View Administrator Static IPs
Block the rest
Virtual Desktops
Virtual Desktops <–> AD/DNS
Dynamic User Logins <–> Specified Internal Resources over Specified protocols
Block the rest
So now that we’ve seen the categories conceptually, let’s look at the service definition and service groups that I came up with. I broke them up into three basic categories.
- Active Directory/DNS
- Horizon View
- User Defined
Let’s take a look at the active directory rules per several microsoft KB’s and some trial and error.
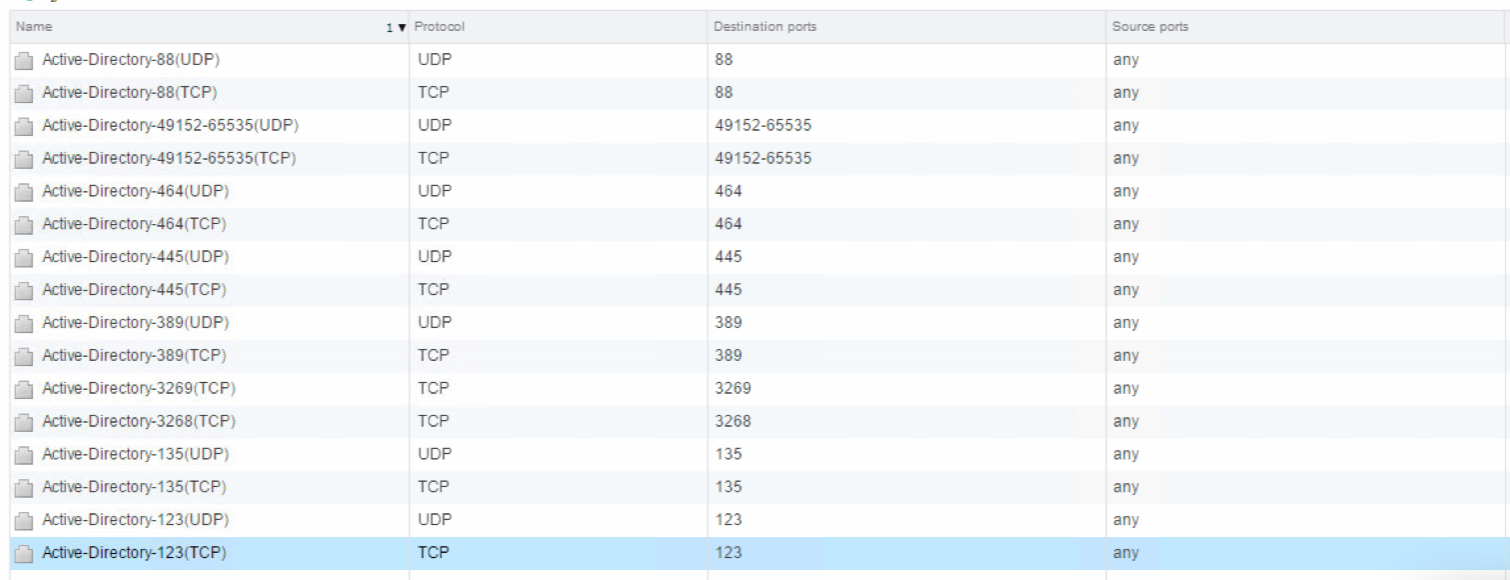
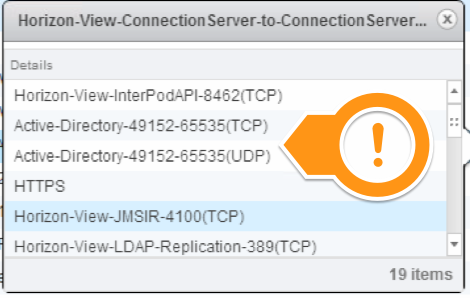
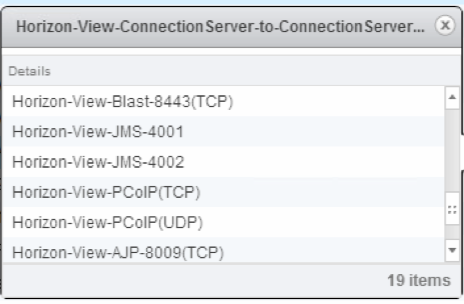
Custom Active Directory Aliases (NSX individual “Services”)
Custom Horizon View Aliases (NSX individual “Services”)
So we can group up those services into service groups for easy clean looking rules. Let’s take a look at those.
View Connection Server <–> vCenter
View Security Server <–> View Desktops
Security Servers <–> Connection Servers
View Desktops <–> Connection Servers
* Interesting note, at the time of writing with View 6.1.1 TCP 4002 was not a documented port requirement in the network requirements KB between desktops and connection servers and I found that it was definitely needed.
View Desktops <–> AD/DNS
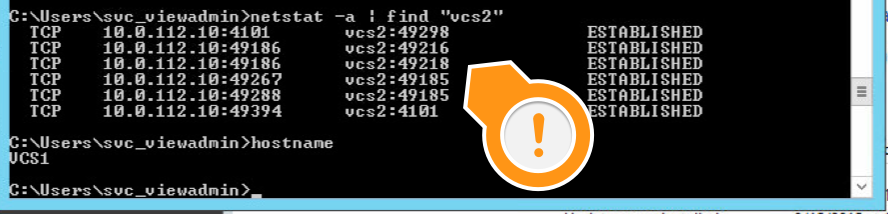
View Connection Server <–> View Connection Server
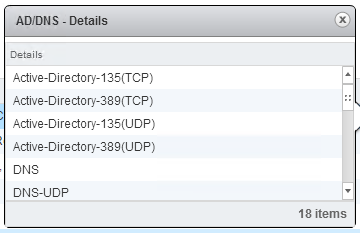
*Note that even though it’s not documented, ADAM requires the random port range. Screen shot below of the connections…
Even though they’re not documented on the network page, I found most ports for AD (ADAM) communication are required from Connection Server to Connection Server. Was able to find this when I kept banging my head during the second connection server install with Log Insight.
User Defined Security Groups
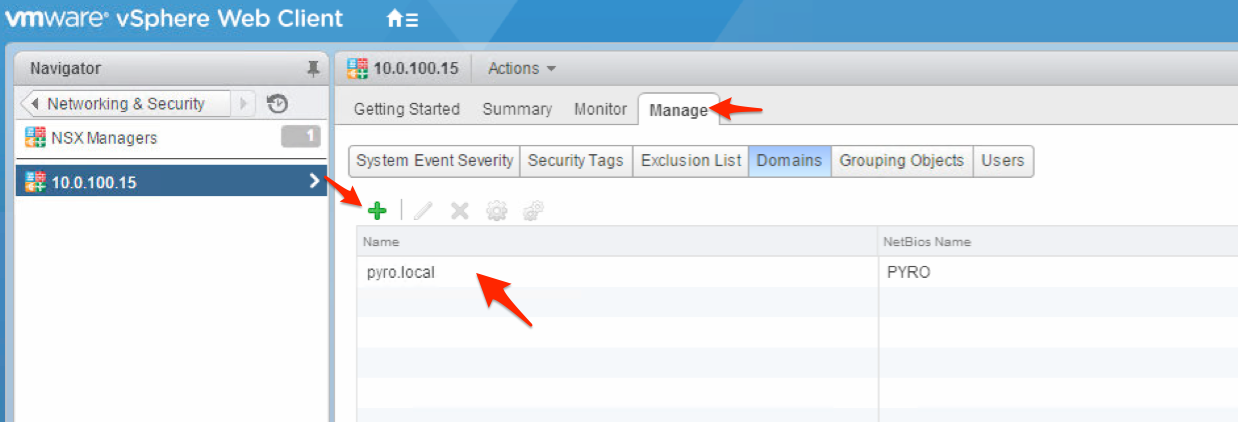
So first of all you have to integrate the NSX manager with Active directory so that you can pull users and allocate ACLs based on users in AD. Do that under the NSX manager \ Manage section and add the domain.
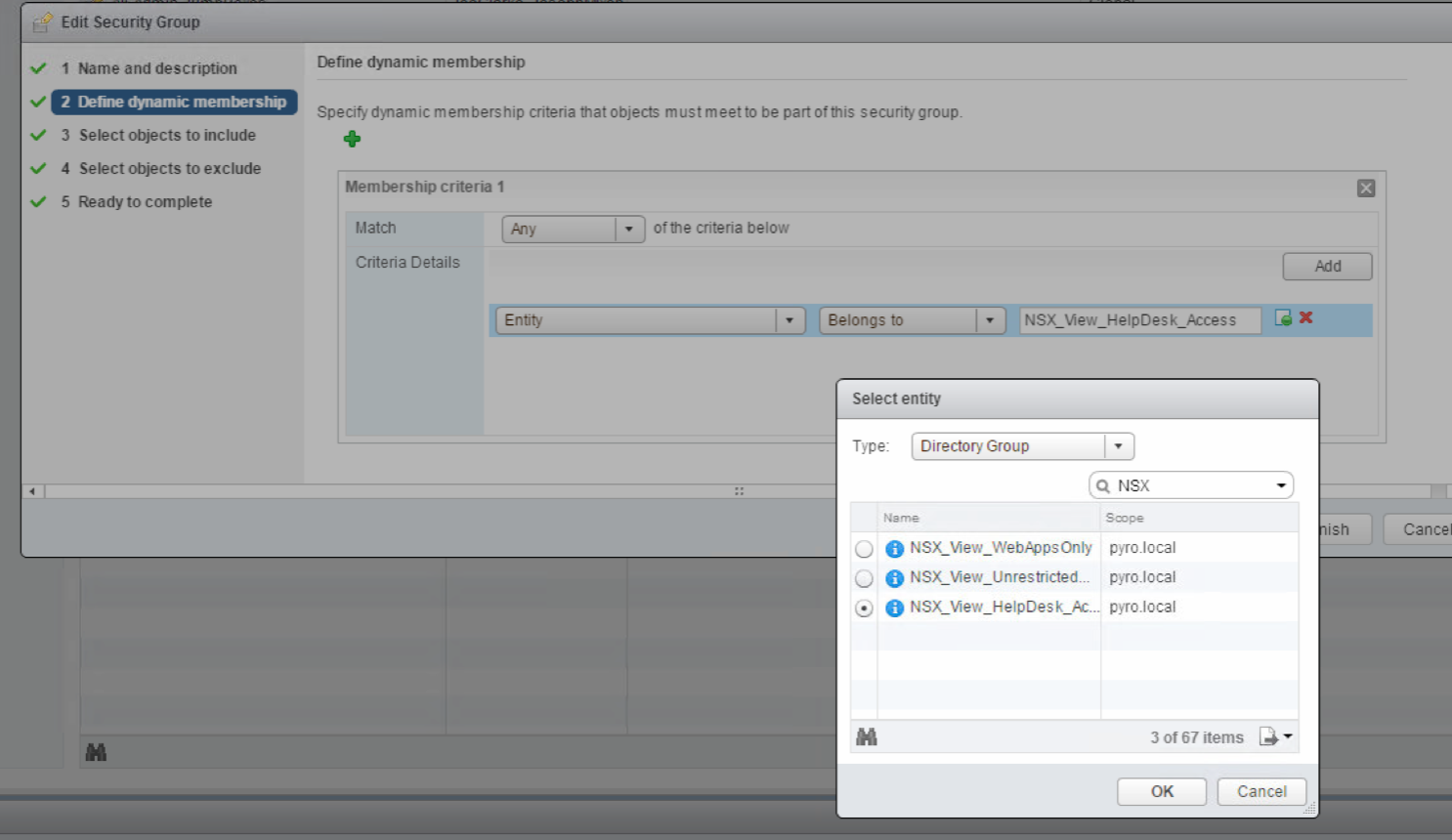
Once the domain is configured, now we can actually add users into the security groups that we’ll use in the firewall rules. Let’s look at one of the dynamic user examples we’ll go over in this post, View Helpdesk staff that need access to the view admin manager web page and the vCenter web interface, but nothing else. Go to the grouping objects then security group and make a new security group:
Then let’s pick the user group out from AD that we already selected. Note the required menus to select the user group.
And finish after excluding anything you want to make sure is always excluded from the security group, eg, domain controllers, whatever. If directory group is not an option, you need to check your domain integration from the previous step.
So now that we’ve defined the source and destination, service groups and dynamic user groups to be firewalled, let’s check out the firewall rules that tie it all together with some commentary.
Desktop_Allow_Rules
I put all the block rules last per norms of DAPE ACL ordering. We can see here that rules 1 & 2 are based on NSX_View_Helpdesk_Access has static access to a couple VMs, View, Log Insight and vCenter via HTTPS.
Most of the security groups for the desktops had dynamic membership based on VM name, such as Win7-, but other filters could be used as well such as OS Windows 7, etc.
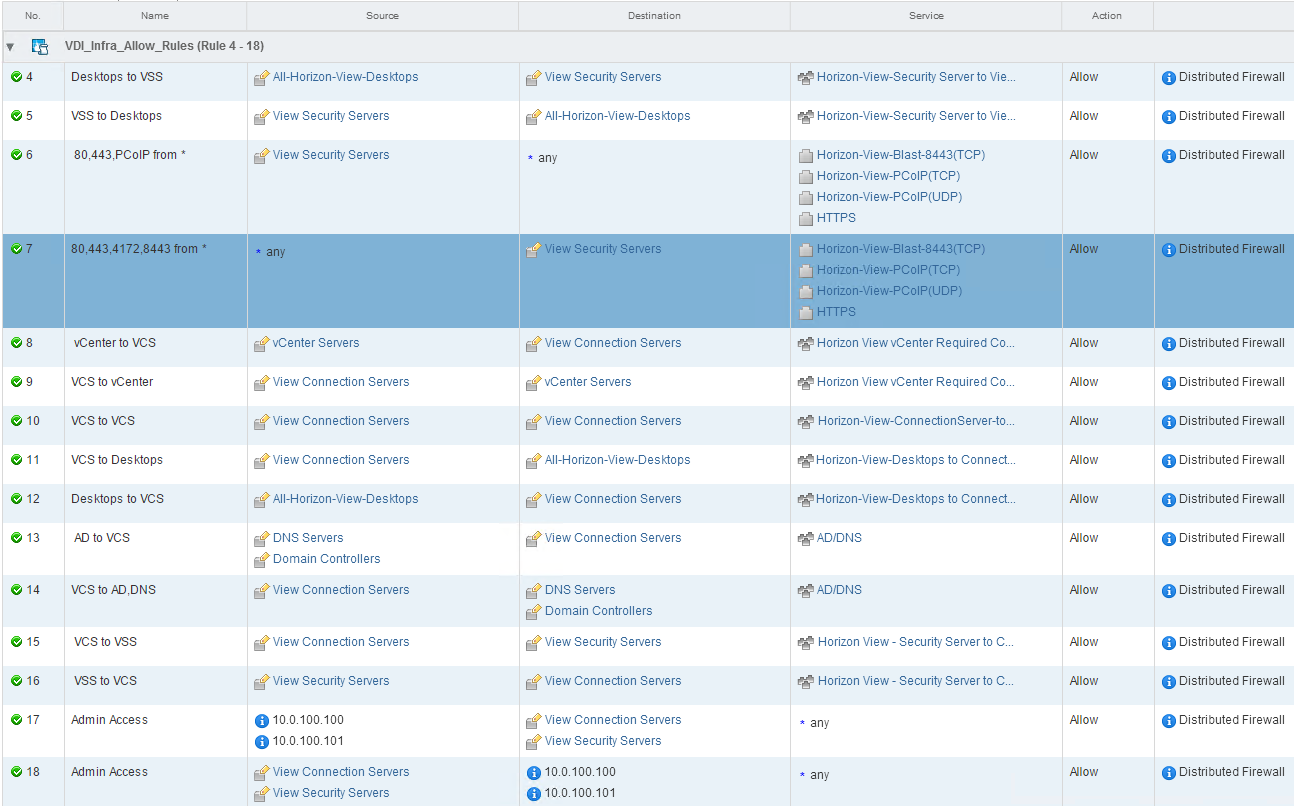
VDI_Infra_Allow_Rules
Here I specified all the required rules in and out of the VDI infrastructure, including open IP stack from a couple manually specified administrator desktop IP addresses. Notice how nobody even has access to the connection servers except the admins?
VDI_Block_Rules
These rules block any traffic in or out of either desktops or security servers unless specified above.
Results are good and as intended.
We can see that dynamically the user on the VM was picked up and the VM was added to the rule.
Big Picture Lessons Learned
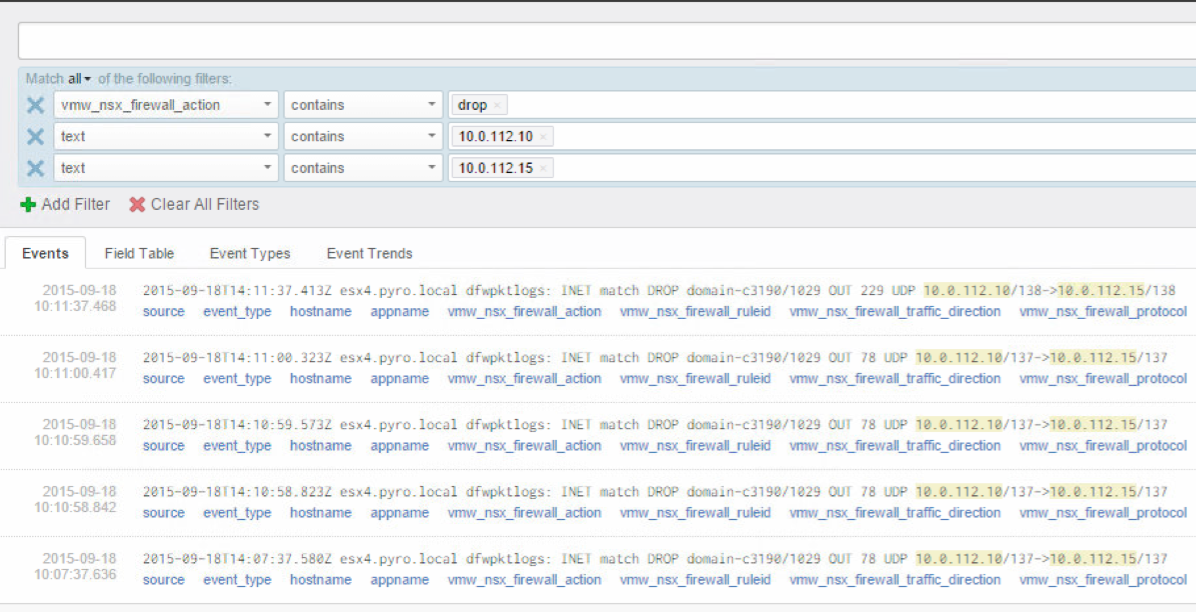
- Knowledge of traffic being dropped by the DFW is paramount, otherwise you’re going to HAVE A BAD TIME, lol (Southpark anyone?). Seriously, though, you need to be able to troubleshoot and loosen ACLs for required traffic and find undocumented port requirements like I had to for View, and they have GREAT network requirement documentation. The best way I came up with to find this information quickly is to log all firewall rules, and then leverage VMware Log Insight with the NSX plugin to filter on drops (installs in like 15 minutes). Made it super simple to figure out what ports were being used between two endpoints. Flow monitoring with NSX 6.2 is another great option to use before putting the rules in place to understand different sources & destinations in play.
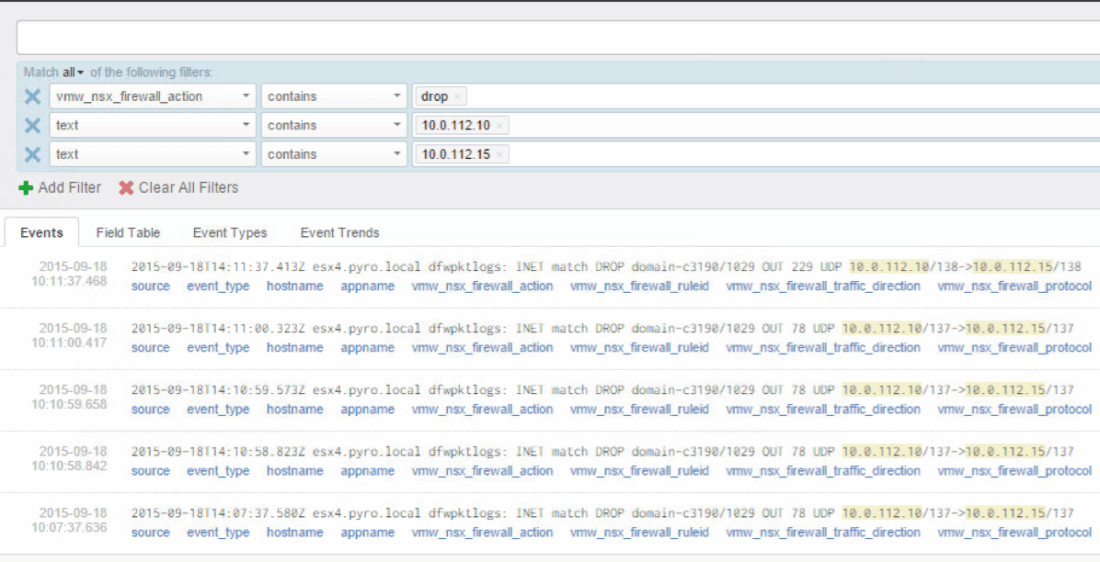
- With NSX 6.1.4, if VMware tools wasn’t running in the VM and vCenter didn’t know the IP address of the VM, none of the DFW rules took effect with the VM selected as the source. Now with 6.2, DFW rules apply whether or not vCenter is aware of the VM ip address. The problem was easy enough to fix with a IP subnet based block catch-all rule, but the point of policy driven access is getting away from static configurations.
- If you change user group membership in AD, you must resync the AD deltas from within the vSphere web client for that to take effect immediately.
- With NSX 6.2, there is a drop-down option when creating the firewall rules to block traffic in/out of the source destination. I found that to completely block traffic in both directions, two rules were required with source destination reversed.
I would absolutely love to give y’all an export of the rules so you could just import them, but sadly it’s not that easy to import them once the XML is exported. As soon as Tristan Todd’s rumored NSX rule import fling is available, I will post a CSV with all the Services, Service Groups and Firewall Rules so you can start with what I put together and automatically import them.
I hope this was helpful for you guys! Next up, I’ll be introducing security server load balancing with NSX, followed by AppVolumes integration, Trend Micro Deep Security AV and hopefully more.