
I really appreciate the article titled “Myth versus Math: Setting the Record Straight on Virtual SAN” as written by Jim Armstrong. He highlights some of the same points I’m going to make in this post. Virtual SAN is a very scalable solution and can be configured to meet many different types of workloads. Also he notes that reference architectures are a starting point, not complete solutions. I am a big fan of hyper-converged architectures such as Virtual SAN. I’m also a big fan of Cisco based server solutions. However, I’ve also had to correct underperforming designs that were based entirely off of reference architectures, and as such I want to ensure that all the assumptions are accounted for with a specific design. One of the reasons I’m writing this is because I have recently delivered a Horizon View Plan and Design which included a Virtual SAN on Cisco hardware, so I wrestled with these assumptions not too long ago. The secondary reason is because this architecture utilizes “Virtual SAN Ready Nodes”, specifically as designed for virtual desktop workloads. Using this vernacular brings trust and immediate, “Oh neat no thinking required for sizing” to most, but I would argue you still have to put on your thinking cap and make sure you are meeting the big picture solution requirements, especially for a greenfield deployment.
The reference architecture that I recently read is linked below.
http://blogs.vmware.com/tap/2015/01/horizon-6-virtual-san-cisco-ucs-reference-architecture.html
Remember, reference architectures establish what is possible with the technology, not necessarily what will work in your house. Let’s go through the assumptions in the above setup now.
Assumption #1: Virtual Desktop Sizing Minimums are OK
Kind of a “duh”. Nobody is going to use big desktop VMs for a reference architecture because the consolidation ratios are usually worse. If you read this article titled “Server and Storage Sizing Guide for Windows 7 Desktops in a Virtual Desktop Infrastructure” it highlights minimum and recommended configurations for Windows 7, which includes the below table.

Some (not all) of the linked clones were configured in this reference utilize 1.5GB 1 vCPU which is below the recommended value. I’ve moved away from the concept of starting with 1 vCPU for virtual desktops regardless of the underlying clock speed, simply due to the fact that a multi-threaded desktop performs better given that the underlying resources can satisfy the requirements. I have documented this in a few previous blog posts, namely “Speeding Up VMware View Logon Times with Windows 7 and Imprivata OneSign” and “VMware Horizon View: A VCDX-Desktop’s Design Philosophy Update“. In the logon times post, I found that simply bumping from 1 vCPU to 2 reduced 10 seconds in the logon time in a vanilla configuration.
Recommendation: Start with 2 vCPU and at least 2GB from a matter of practice with Windows 7 regardless of virtual desktop type. You can consider bumping some 32 bit use cases down to 1 vCPU if you can reduce the in-guest CPU utilization by doing things like offloading PCoIP with an Apex card, or utilizing a host based vShield enabled AV protection instead of in-guest. Still, you must adhere to the project and organizational software requirements. Size in accordance with your desktop assessment and also POC your applications in VMs sized per your specs. Do not over commit memory.
Assumption #2: Average Disk Latency of 15ms is Acceptable
This reference architecture assumes from a big picture that 15ms of disk latency is acceptable, per the conclusion. My experiences have shown me that between 7ms of average latency is the most I’m willing to risk on behalf of a customer, with the obvious statement “the lower the better”. Let’s examine the 800 linked clone desktop latency. In that example, the average host latency was 14.966ms. Most often times requirement #1 on VDI projects I’m engaged on is acceptable desktop performance as perceived from the end user. In this case, perhaps more disk groups, more magnetic disks or smaller and faster magnetic disks should have been utilized to service the load with reduced latency.
Recommendation: Just because it’s a hyper converged “Virtual SAN Ready Node” doesn’t mean you’re off the hook for the operational design validation. Perform your View Planner or LoginVSI runs and record recompose times on the config before moving to production. When sizing, try to build so that average latency is at or below 7ms (my recommendation), or whatever latency you’re comfortable with. It’s well known that Virtual SAN cache should be at least 10% of the disk group capacity, but hey, nobody will yell at you for doing 20%. I also recommend the use of smaller 15K drives when possible in a Virtual SAN for VDI, since they can handle more IO per spindle, which fits better with linked clones. Need more IO? Time for another disk group per host and/or faster disk. Big picture? You don’t want to dance with the line of “enough versus not enough storage performance” to meet the requirements in a VDI. Size appropriately in accordance with your desktop assessment, beat it up in pre-prod and record performance levels before users are on it. Or else they’ll beat you up.
Assumption #3: You will be handling N+1 with another server not pictured
In the configuration used, N+1 is not accounted for. Per the norm in most reference architectures, it’s taken straight to the limit without thought for failure or maintenance. 800 desktops, 8 hosts. The supported maximum is 100 Desktops/Host on Virtual SAN due to the maximum amount of objects supported per host (3000) and the amount of objects and linked clones generate. So while you can run 800 desktops on 8 hosts, you are officially at capacity. It is noted that several failure techniques were demonstrated in the reference, however the failure of an entire host was not one of them. Simulated failure of SSD Disk, magnetic disk and network were tested but an entire host failure was not simulated.
Recommendation: Size for at least N+1. Ensure you’re taking 10% of the pCores away when running your pCores/vCPU consolidation ratios for desktops to account for the 10% Virtual SAN CPU overhead. Ensure during operational design validation that the failure of a host including a data resync does not increase disk workload in such a fashion that it negatively impacts the experience. In short, power off a host in the middle of a 4 hour View Planner run and watch the vsan.observer for disk latency one hour later during the resync.
Assumption #4: Default policy of FTT=0 for Linked Clones is Acceptable
I disagree with the mindset that FTT=0 is acceptable for linked clones. In my opinion it provides a low quality configuration as the failure of a single disk group can result in lost virtual desktops. The argument in favor of FTT=0 for stateless desktops is “So what? If they’re stateless, we can afford to lose the linked clone disks, all the user data is stored on the network!” Well that’s an assumption and a fairly large shift in thinking especially when trying to pry someone away from the incumbent monolithic array mentality. The difference here is that the availability of the storage on which the desktops reside is directly correlated with the availability of the hosts. If one of the hosts restarts unexpectedly, with FTT=0 the data isn’t really lost, just unavailable while the host is rebooting. However if a disk group suffers data loss, it makes a giant mess of a large number of desktops that you end up having to clean up manually, since the desktops are unable to be removed from the datastore in an automated fashion by View Composer. There’s a reason the KB which describes how to clean up orphaned linked clone desktops is complete with two YouTube videos. This is something I’ve unfortunately done many times, and wouldn’t wish upon anyone. Another point of design concern is that if we’re going to switch the linked clone storage policy from FTT=0 to FTT=1, now we’re inducing a more IO operations which must be accounted for across the cluster during sizing. Another point of design concern is that without FTT=1, the loss of a single host will result in some desktops that get restarted by HA, but also some that may only have their disk yanked. I would rather know for certain that the unexpected reboot of a single host will result only in the state change of desktops located on that host, not a state change of some desktops and the storage availability for others called into question. The big question I have in regards to this default policy is: Why would anyone move to a model that introduces a SPOF on purpose? Most requirements dictate removal of SPOFs wherever possible.
Recommendation: For the highest availability, plan for and utilize FTT=1 for both linked clone and full desktops when using Virtual SAN.
The default linked clone storage policy is pictured below as installed with Horizon View 6.
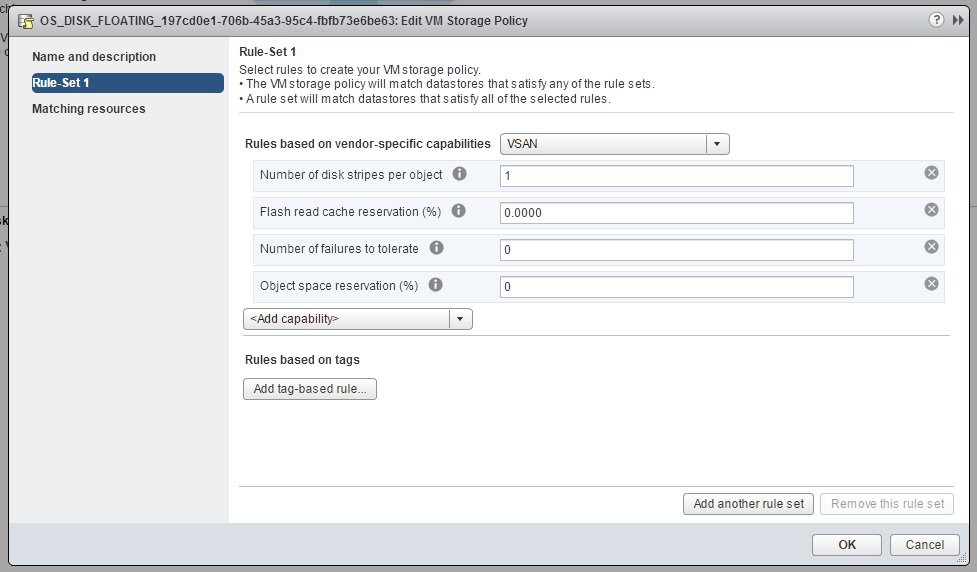
Assumption #5: You’re going to use CBRC and have accounted for that in your host sizing
Recommendation: Ensure that you take another 2GB of memory off each host when sizing to allow for the CBRC (content based read cache) feature to be enabled.
That’s all I got. No disrespect is meant to the team of guys that put that doc together, but some people read those things as the gold standard when in reality:

