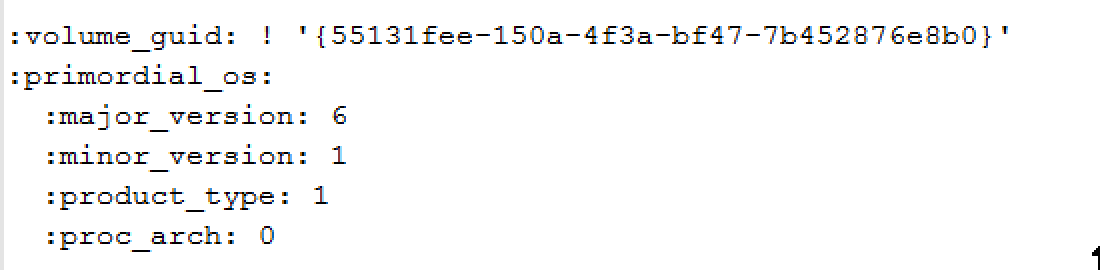I had some of these tough questions about AppVolumes when it first came out. I set out to answer these questions with some of my own testing in my lab. These questions are beyond the marketing and get down to core questions about the technology, ongoing management and integrations. Unfortunately I can’t answer all of them, but these are some of my observations after working in the lab with it and engaging some peers. Much thanks to @Chrisdhalstead for the peer review on this one. Feedback welcome!
Q. Will AppVolumes work running on a VMware Virtual SAN?
A. Yes! My lab is running entirely on the Virtual SAN datastore and AppVolumes has been working great for me on it.
Q. Can I replicate and protect the AppStacks and Writable volumes with vSphere Replication or vSphere Data Protection, or is array based backup/replication the only option?
A. At the time of writing I’m pretty sure the only way to do this is to replicate the AppStacks is with array based replication. Of course, you could create a VM that serves storage to the hosts and replicate that, but that’s not an ideal solution for production. Hopefully more information will come out on this in the near future. This means that currently, there’s no automated supported method that I’m aware of to replicate the volumes when Virtual SAN is used for the AppStacks and writable volumes. Much thanks to the gang on twitter that jumped in on this conversation: @eck79, @jshiplett, @kraytos, @joshcoen, @thombrown
Q. So let’s talk about the DR with AppVolumes. Suppose I replicate the LUNs with array based replication that has my AppStacks and Writable Volumes on it. What then?
A. First of all, this is a big part of the conversation, and from what I hear there are some white papers brewing for this exact topic. I will update this section when they come out. My first thought is for environments that have the highest requirements for uptime which are active/active multi-pod deployments. My gut reaction says that while you can replicate, scan and import AppStacks for the sake of keeping App updating procedures relatively simple, I’m not sure how well that’s going to work with writable volumes when there is a user persona with actively used writable volumes in one datacenter. The same problem exists for DFS, you can only have a user connect from one side at the time, (connecting from different sides simultaneously with profiles is not supported) so we generally need to give users a home base. However, DFS is an automated failover in that replication is constantly synching the user data to the other site and is ready to go. So for that use case, first determine if profile replication is a requirement or if during a failure it’s OK for users to be without profile data. If keeping the data is a requirement, I’d say you should probably utilize a UEM with replicating shares with DFS or something similar. For active/warm standby, the advice is the same. For active/standby models, you’ll have to decide if you’re going to replicate your entire VDI infrastructure and your AppVolumes, or if you’re going to set up infrastructure on both sides.
Q. But after replication how will AppVolumes know what writable volumes belong to what user? Or what apps are in the AppStacks?
A. That information is located in the metadata. It should get picked up when re-scanning the datastore from the Administrative console. I’m sure there’s more to it than that, but I don’t have the means to test a physical LUN replication at the moment. Below is an example of what is inside the metadata files. This is what’s picked up when the datastore is scanned via the admin manager.
Q. What about backups? How can I make sure my AppStacks are backed up?
A. Backing up the SQL database is pretty easy and definitely recommended. To back up the AppStacks, that means that you should consider and evaluate a backup product that will allow for granular backups down to the virtual disk file level on the datastore. This doesn’t include VDP. Otherwise you’re going to have to download the entire directory the old fashioned way, or scp the directory to a backup location on a scheduled basis.
Q. In regards to application application conflicts between AppStacks and Writable Volumes, who wins when different versions of the same app are installed? How can I control it?
A. My understanding is that the last volume that was mounted wins. In the event a user has a writable volume, that is always mounted last. By default, they are mounted in order of assignment according to the activity log in my lab. If there is a conflict between AppStacks, you can change the order in which they are presented. However, you can only change the order for all AppStacks that are assigned to the same group or user. For example, if you have 3 AppStacks and each of them are assigned to 3 different AD groups, there’s no way to control the order of assignment. If 3 AppStacks that are all assigned to the same AD group, you can override the order in which they are presented under the properties of the group.
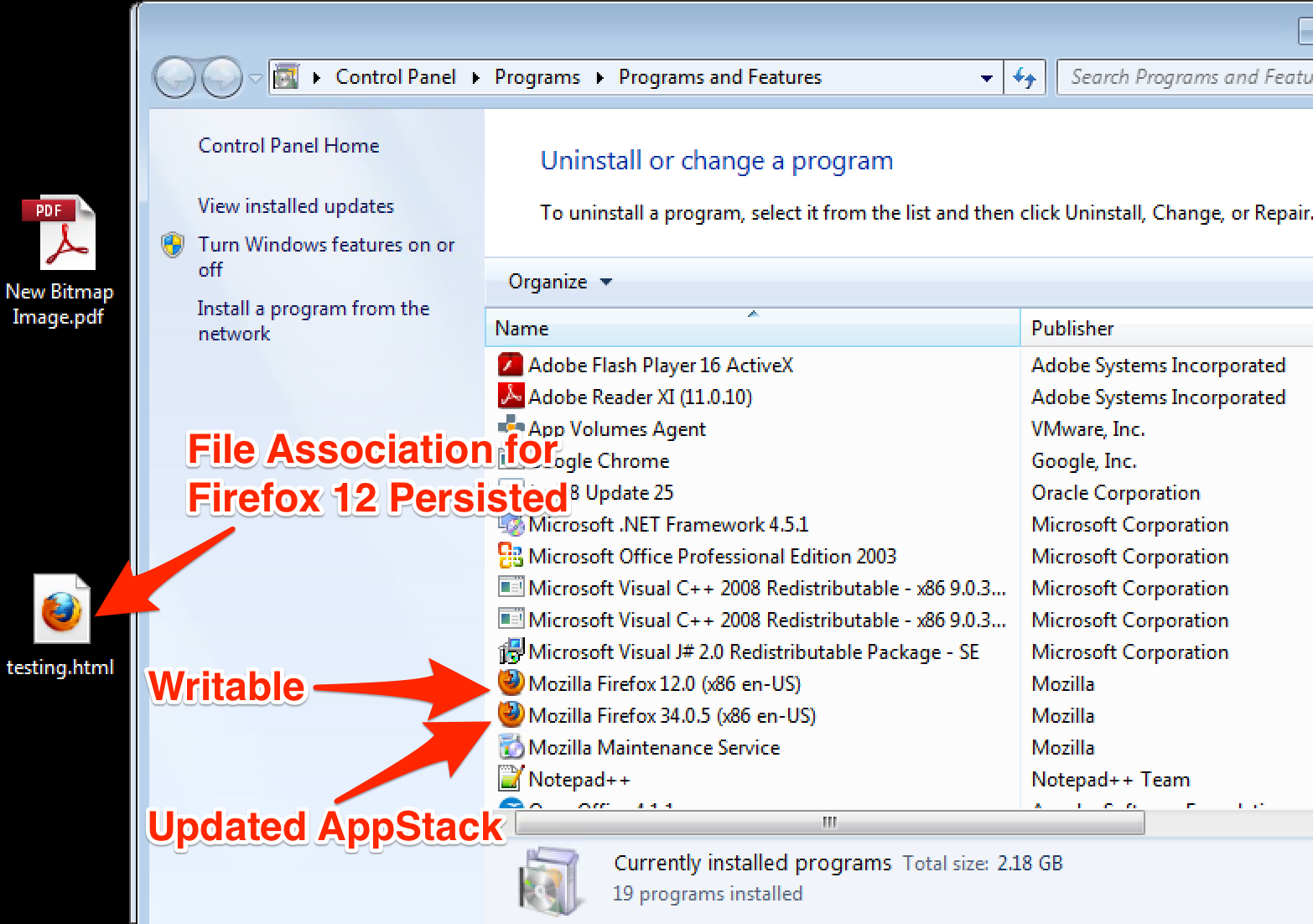
Q. What happens if I Update an AppStack with an App that a User already installed in their writable volume? For example, if a user installed Firefox 12 in their writable volume, then the base AppStack was updated to include Firefox 23, what happens when the AppStack is updated?
A. My experience in the lab shows that when a writable volume is in play for a user, anything installed there that conflicts will trump what is installed in an AppStack. Also all file associations regardless of applications installed in the underlying AppStacks are trumped by what has been configured in the user profile and persisted in the writable volume. Also, my test showed that if you remove the application from the writable volume and refresh the desktop, the file associations will not change to what is in the base AppStack.
After the update:
Files in the C:\Program Files\ Directory were still version 12.
Q. What determines what is captured via UIA on a user’s writable volume and what is left on the machine?
A. Again, another thing I’m not sure of. I know that there must be some trigger or filter but it is not configurable. I was able to test and verify that all of these files are kept:
All Files in the users’ profile
Wallpapers
Printers
AppData
HKCU Registry Settings
Windows Explorer View Options such as File Extensions, hidden folders
Q. Can updates be performed to the App Stacks without disruption of the users that have the App Stack in use?
A. Yes. While it is true that you must unassign the old version of the AppVolume first, you can choose to wait until next logon/logoff. Then you can assign the new one and also choose to wait until the next logon/logoff. There is a brief moment after you unassign the AppStack that a user might log in and not get their apps, so off hours is probably a good time to do this in prod unless you’re really fast on the mouse.
Q. If one AppStack is associated to one person, what about people that need access to multiple pools or RDSH apps simultaneously?
A. A user can have multiple AppStacks that are used on different machines. You can break it down so they are only attached on computers that start with a certain hostname prefix and OS type.
Q. So if an RDSH computer has an AppStack assigned to the computer, can you use writable volumes for the user profile data?
A. No. It is not supported to have any user based AppStack or writable volumes assigned with a computer based AppStack is assigned to the machine.
Q. So can I still use AppVolumes to present apps with RDSH?
A. Sure you can, it just has to be machine based assignments only; you just can’t use user based assignments or writable volumes at the same time. While we’re on the topic there’s no reason you couldn’t present AppStacks to XenApp farms too, it’s what CloudVolumes originally did. My recommendation is to use a third party UEM product for profiles when utilizing RDSH app delivery, trust me that it’s something you’re going to want granular control over.
Q. What about role based access controls for the AppVolumes management interface? There’s just an administrator group?
A. Correct, there’s no RBAC with the GA release.
Q. Does this integrate with other profile tool solutions?
A. Yes. I’ve used Liquidware Labs Profile Unity to enable automatic privilege elevation for installers located on specified shares or local folders. This way can install their own applications (providing they’re located on a specified share) which will be placed in the writable volume, or they can one-off update apps that have frequent updates without IT intervention right in the writable volume.